【项目00】Python数学分析开发环境安装配置
作者:欧新宇(Xinyu OU)
当前版本:Release v4.0
开发平台:Anaconda 2024.02
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2024年3月3日
本安装说明为 "Python数学分析开发环境安装配置" 的安装指南,适用于《数学建模》, 《财经大数据分析》等课程。需要参考《深度学习》、《计算机视觉》等人工智能课程安装说明请访问Python机器学习环境的安装和配置(发布版)。本教案基于Python集成安装包Anaconda,同时使用VSCode编程环境和JupyterLab编程环境作为开发环境。VScode适用于调试完整的Python代码,并将整个项目的所有代码都保存为*.py文件进行发布。Jupyterlab适用于独立代码和模型的调试,特别适合于数据分析和可视化分析。
本项目中需要使用pip从服务器端安装部分软件,为提高下载速度,建议加载清华的源或阿里的源:
清华源:pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simple阿里源:pip install xxx -i https://mirrors.aliyun.com/pypi/simple
原则上,安装顺序请按照以下序号流程。
一. Python环境的安装和配置
1.1 Python的安装
Python编程环境的安装包含两种方法:
- 基于Python官网原生Python安装程序(不推荐)
- 基于第三方封装版Python,此处推荐Anaconda。Anaconda包含了大量的Python库函数,包括机器学习开发库scikit-learn,基础科学计算库Numpy,数据分析工具Pandas,绘图库Matplotlib、数据分析库Scipy、图论库networkx等。
- 版本:Anaconda3-2024.02-Windows-x86_64,Python版本3.11
- URL:https://www.anaconda.com/products/individual
- 安装过程较为简单,但后续需要安装各种库时,均需要打开【Anaconda Prompt (Anaconda3)】命令提示行进行安装,包括在《程序设计基础(Python)》课程中使用到的jieba中文分词库和wordcloud词云库,及本课程需要用的cvxopt和cvxpy库。
安装时,应务必注意:1. 勾选"Install for Just Me"; 2. 将相关链接库文件添加到PATH中。
1.2 Python环境的测试
# 测试用例一: Hello world!
print("Hello world!")
Hello world!
1.3 安装Python课程所需要的其他库文件
-
安装凸优化处理库
>> pip install cvxopt -i https://pypi.tuna.tsinghua.edu.cn/simple
>> pip install cvxpy -i https://pypi.tuna.tsinghua.edu.cn/simple -
安装jieba库
>> pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple -
安装wordcloud词云库
>> pip install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple
二. 集成开发环境的安装和配置
2.1 Visual Studio Code (VSCode) 编程环境的安装与配置
- VSCode是当今最流行的集成开发环境,不仅适用于Python,也同样适用于Html+CSS、Javascript及php等Web前端的开发,同时也支持Java、C++、C等程序的开发。类似的集成开放环境还有PyCharm、Sublime。安装过程较简单,不再累述。
- URL:https://code.visualstudio.com/Download
2.2 JupyterLab 编程环境的安装与配置
JupyterLab是Anaconda内置的Jupyter Notebook的升级版,完全兼容Notebook开发环境,但在使用上更方便,也集成了一些新的特性。
2.2.1 JupyterLab的安装
自最新版本的 Anaconda3-2021.11-Windows-x86_64 已内置了JupyterLab3.2.1,因此无需再手动安装。此外,新版的VSCode也内置了'.ipynb'文档的编辑环境,可以直接进行使用。
2.2.2 更新JupyterLab内核(可选)
>> conda update jupyter_core jupyter_client
2.2.3 JupyterLab的配置 (可选)
JupyterLab最重要的配置是初始路径的设置,下面介绍一种最简单有效的方法:在桌面创建批处理(*.bat)快捷方式,并直接双击启动JupyterLab。该方法可以实现多个路径的同时配置。
1.在桌面上新建一个文本文件,输入以下字段
C:\Users\Administrator\anaconda3\Scripts\jupyter-lab.exe D:\Workspace\DeepLearning
PS: 以上文件包含两个路径,前者为jupyter-lab.exe的路径,后者为工作任务路径。当存在多个工作任务时,只需为每个工作任务单独建立一个bat批处理文件即可
2.将文件另存为MyJupyterLab.bat (或DeepLerning.bat, ComputerVision.bat, ComputerMath.bat)
3.使用时,只需要双击该批处理(*.bat)文件即可
三. 数学建模必需库的安装和测试
基于Anaconda开发包安装的Python,已经包含了大多数机器学习和数据分析所需的第三方库,因此不需要再进行额外安装。但如果是基于官方版的Python,则需要额外进行安装,请各位自行查阅安装方法。
1. 优化算法环境测试
运行如下代码,如果能绘制出曲线图,则说明优化算法环境测试通过。
import cvxpy as cp # 载入凸优化包
import matplotlib.pylab as plt # 载入绘图程序包
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
q = plt.array([0.025, 0.015, 0.055, 0.026])
r = plt.array([0.05, 0.27, 0.19, 0.185, 0.185])
x = cp.Variable(5, pos=True)
aep = plt.array([1, 1.01, 1.02, 1.045, 1.065])
obj = cp.Maximize(r @ x)
a = 0; aa = []; Q = []; X = []; M = 10000; # 设置初始风险率为0,增长上限为0.05
while a <= 0.05:
con = [aep @ x == M, cp.multiply(q, x[1:])<=a*M]
prob = cp.Problem(obj, con)
prob.solve(solver=cp.GLPK_MI)
aa.append(a); # aa用于保存不同风险下的风险率向量
Q.append(prob.value) # 将不同风险下的收益保存进变量Q中,以便可视化
X.append(x.value) # X为投资组合向量
a = a + 0.001
plt.figure(figsize=(6,3))
plt.plot(aa, Q, 'r*');
plt.xlabel('风险率a')
plt.ylabel('收益Q', rotation=0);
plt.show()

2. Numpy 基础科学计算库
Numpy是Python中最基础的科学计算库,它的功能主要包括高位数组(Array)计算、线性代数计算、傅里叶变换以及产生伪随机数等。Numpy是机器学习库scikit-learn的重要组成部分,因为机器学习库scikit-learn主要依赖于数组形式的数据来进行处理。
更多信息请参考:RUNOOB站的Numpy栏目:https://www.runoob.com/numpy/numpy-tutorial.html
【知识点】Numpy基础科学库极简使用说明
以下代码用于测试和生成一个数组。
# 使用import关键字引入numpy库,为了简便使用缩写 “np”来表示numpy库。
import numpy as np
# 定义一个变量 i, 用于保存数组
i = np.array([[12,34,56],[78,90,11]])
# 输出变量 i
print("i = \n{}".format(i))
i = [[12 34 56]
[78 90 11]]
3. Scipy 科学计算工具集
Scipy是Python中用于进行科学计算的工具集,它可以实现计算机统计学分布、信号处理、线性代数方程等功能。在机器学习中,稀疏矩阵的使用非常频繁,Scipy库中的sparse函数可以用来生成这种稀疏矩阵。稀疏矩阵用于存储那些大部分数值为0的np数组。以下代码用使用sparse()函数生成和测试稀疏矩阵。
# 对scipy的使用需要利用from关键字来引用其内部的子库
import numpy as np
from scipy import sparse
# 使用numpy的eye()函数生成一个6行6列的对角矩阵
# 矩阵中对角线上的元素值为 1,其余元素为 0
matrix = np.eye(6)
# 将np数组转化为 CSR格式的Scipy稀疏矩阵 (sparse matrix)
sparse_matrix = sparse.csr_matrix(matrix)
# 输出对角矩阵
print("对角矩阵:\n{}".format(matrix))
对角矩阵:
[[1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]]
4. Pandas 数据分析工具
Pandas是Python中进行数据分析的库,它具有以下功能
- 生成类似Excel表格式的数据表,并对数据进行修改操作;
- 从不同的数据源中获取数据,例如:SQL Server, Excel表格, CSV文件, Oracle等;
- 在不同的列中使用不同的数据类型,例如:整型,浮点型,字符串型等。
- 更多信息请参考“Pandas中文网”,URL:https://www.pypandas.cn
# 使用import关键字引入pandas库,为了简便使用缩写 “pd”来表示pandas库。
import pandas as pd
# 使用字典数据类型创建一个数据表,并用pandas库的DataFrame数据结构进行显示
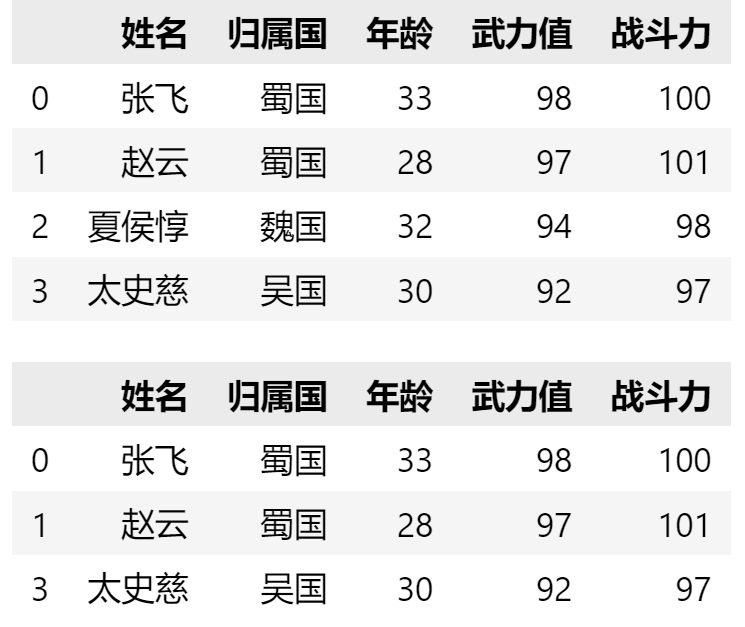
data = {"姓名":["张飞","赵云","夏侯惇","太史慈"],
"归属国":["蜀国","蜀国","魏国","吴国"],
"年龄":[33,28,32,30],
"武力值":[98,97,94,92],
"战斗力":[100,101,98,97]
}
data_frame = pd.DataFrame(data) # 将字典数据类型转换成pandas数据类型
display(data_frame) # 值得注意的是display是Jupyter-iPython内置函数,所以在VS中是不起作用。
# 如果想要把一些数据段进行排除,可以使用查询语句来实现。例如,不显示“魏国”的武将信息
# 使用 “不等于 !=” 操作符排除字段中包含特定值的数据
display(data_frame[data_frame.归属国 != "魏国"])
5. Matplotlib 绘图库
matplotlib是Python中最重要的绘图库,它可以生成出版质量级别的图形,包括折线图、散点图、直方图等。
- 具体信息可以参考RUNOOB的matplotlib板块:https://www.runoob.com/w3cnote/matplotlib-tutorial.html
- 英语不错的同学,可以直接访问matplotlib项目页:http://matplotlib.org
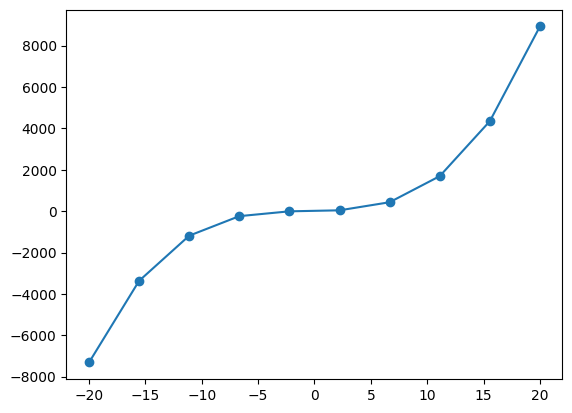
以下代码用于生成一个表达式为: 的曲线图。
# 通过inline指令,实现在Jupyter中的实时绘图功能
%matplotlib inline
# 1. 使用import关键字引入matplotlib库,为了简便使用缩写 “plt”来表示matplotlib库。
import matplotlib.pyplot as plt
import numpy as np
# 使用linspace()函数生成一个-20到20,元素个数为10的等差数列。
# 令数列中的值为 x, 并根据表达式计算对应的 y值。
x = np.linspace(-20, 20, 10)
y = x**3 + 2*x**2 + 6*x + 5
#使用plot()函数绘制出曲线图
plt.plot(x, y, marker = "o")
print("x={}".format(np.round(x, 2)))
print("y={}".format(np.round(y, 2)))
x=[-20. -15.56 -11.11 -6.67 -2.22 2.22 6.67 11.11 15.56 20. ]
y=[-7315. -3368.44 -1186.5 -242.41 -9.43 39.18 430.19 1690.32
4346.34 8925. ]
6. scikit-learn 机器学习库
scikit-learn是Python中最重要的机器学习模块之一。它基于Scipy库,在不同的领域中已经发展出大量基于Scipy的工具包,它们被统一称为Scikits,其中最著名的一个分支就是scikit-learn。它包含众多的机器学习算法,主要分为六大类:分类、回归、聚类、数据降维、模型选择和数据预处理。下列给出一个使用scikit-learn进行分类的简单例子。在下例中会随机生成包含300个具有两种属性数据的数据集,然后利用简单的SVM分类器实现分类。
6.1 加载分类模型和可视化模块所需要的库文件
# 载入基础科学计算库 numpy
import numpy as np
# 载入可视化数据的模块 matplotlib
import matplotlib.pyplot as plt
# 从scikit-learn 库中载入预处理模块, 数据生成模块, 数据分割模块(划分为
# 训练集和测试集)和 支持向量机SVM的Support Vector Classifier分类模块
from sklearn.datasets import make_blobs
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
6.2 生成数据集
# 生成300个具有2种属性的数据
X, y = make_blobs(n_samples=300, n_features=2, random_state=22)
6.3 可视化数据并计算分类精度
#可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
# 实现数据的正则化,可以有效提高分类精度
X = preprocessing.scale(X)
# 使用 train_test_split() 函数,将样本分割为 train训练集和 test测试集,
# 其中测试集数量为 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 定义SVC的核函数
clf = SVC(gamma = "auto")
# 使用fit()函数对模型进行训练
clf.fit(X_train, y_train)
# 使用 test测试集输出测试准确率
print('{:.5f}'.format(clf.score(X_test, y_test)))
0.98889